사용 중인 그래픽 환경에 글자 드로잉 시스템을 부여하는 과정을 간략히 기록한 글이다.
(M)SDF 서체
컴퓨터로 글자를 그리는 여러 방법이 있지만, 프래그먼트 셰이더를 이용해 디스플레이를 구성하는 하나의 픽셀 색상을 정해 그림을 그려내는 상황에서 우리가 사용할 수 있는 가장 좋은 방법은 부호 거리 장(Signed Distance Field, SDF), 혹은 다중 채널 부호 거리 장(Multi-channel Signed Distance Field, MSDF)을 이용하는 것이다.
이름이 복잡해 보이지만, 결국은 서체 파일에 들어 있는 모든 글리프를 담은 커다란 이미지 파일을 만들어 사용하는 기법이다. SDF를 이용한다는 것은 ‘거리 정보’를 단일 채널에 담은 글자 이미지를 사용한다는 뜻이며, MSDF를 이용한다는 것은 그 거리 정보를 여러 채널로 분할해 담은 이미지를 사용한다는 뜻이다. 즉, 글자 형태의 경계로부터 떨어진 거리값으로 형태를 정의한 이미지를 가지고 글자를 그리는 것이다.
여기서 의문이 생긴다. 왜 굳이 경계와의 거리를 이용해야 할까? 글자 이미지 파일을 사용하는 것이라면 글자 형태의 비트맵 이미지를 써도 무방하지 않은가? 무방하다. 단, 글자 크기가 고정되어 있고, 확대·축소가 일어나지 않으며, 텍스트 양이 적은 경우에만 그렇다. 굳이 SDF 이미지를 사용하는 까닭은 글자 크기 변화에 강하고, 글자에 다양한 처리를 가하기 용이하며, 텍스처 메모리를 줄일 수 있기 때문이다. 그렇기에 주로 게임처럼 시점에 따라 글자 크기가 동적으로 변하는 매체에서 사용된다. 이 기술이 사용된 게임 중에는 밸브의 『팀 포트리스 2』도 있는데, 게임 내에서 스프레이로 벽에 글자를 칠하는 기능에 활용된 것으로 보인다.



폰트 아틀라스 생성
서체 파일 하나의 모든 글리프 이미지를 포함하는 커다란 이미지 파일을 SDF・MSDF 폰트 아틀라스(서체 판)라고 한다. 그렇다면 직접 만들어 보자. 물론 이미지 편집 프로그램을 이용해 일일이 만들 수 있겠지만 이미 그보다 나은 방법들이 존재한다. 그 중 Chlumsky가 제작한 msdf-atlas-gen이라는 프로그램을 이용할 것이다. 설치한 후 실행 명령을 통해 폰트 파일을 서체 판으로 만들 수 있다. 형태 경계까지의 거리로 이루어진 png 이미지파일 하나와, 이에 대한 정보를 담고 있는 json 파일, 총 두 개의 파일을 결과물로서 얻을 수 있다. 이제 이를 이용해 글자를 그리면 된다.
길형진 디자이너 프리텐다드 SDF 서체 판
한글 서체의 경우 11172자 이상이 될 수 있기에 글자 판 또한 매우 커질 수 있다. 이를 방지하기 위해 2350자 만을 포함하는 이미지를 제작하였다. 이를 셰이더 프로그램에 텍스처로 전달하여 이용할 것이다.

지금은 화면 가로・세로를 0부터 1 사이의 값으로 이용하고 있고, 원점이 화면 왼쪽 아래인 상황이다. 텍스처는 기본적으로 왼쪽 위를 원점으로 하기에 뒤집혀 그려지고 있다. 화면 좌표의 원점을 가운데로 변경하고, 0부터 1의 값에 화면 비율을 보정하여 실제 화면 모양에 맞게 조정할 필요가 있다.

글자 그리기
현재는 그저 서체 판 전체를 그려내고 있다. 우선 “가”를 그려보자. 서체의 정보를 담고 있는 json 파일은 아래와 같이 구성되어 있다.
| 구성 요소 | 의미 |
|---|---|
atlas |
서체 판 전체 정보 |
metrics |
폰트 전체의 줄 높이, baseline 관련 정보 |
glyphs |
문자별 렌더링 정보 목록 |
unicode |
어떤 문자인가 |
advance |
다음 글자로 이동할 거리 |
planeBounds |
화면에 배치할 글자 사각형 |
atlasBounds |
서체 판 텍스처에서 잘라 읽을 사각형 |
{
"unicode": 44032,
"advance": 0.8642578125,
"planeBounds": {
"left": -0.11991749142768079,
"bottom": -0.21612635078969242,
"right": 0.97733936642768082,
"top": 0.92768079800498759
},
"atlasBounds": {
"left": 2248.5,
"bottom": 7846.5,
"right": 2413.5,
"top": 8018.5
}
},모든 글리프마다 planeBounds, atlasBounds, advance 등의 값을 가지고 있다. planeBounds와 atlasBounds는 left, right, top, bottom의 네 가지 값으로 이루어져 있다.
// atlasBounds의 각 값을 텍스처 해상도 값으로 나눈다
let u0 = 2248.5 / 8192;
let v0 = 7846.5 / 8192;
let u1 = 2413.5 / 8192;
let v1 = 8018.5 / 8192;
// 글자 왼쪽 아래, 글자 오른쪽 위, 0부터 1로 영역 샘플링
let uvMin = vec2f(u0, v0);
let uvMax = vec2f(u1, v1);atlasBounds는 텍스처 아틀라스 안에서 특정 글자 이미지가 들어 있는 픽셀 영역을 의미한다. 우선 텍스처에서 이 사각형을 잘라 0부터 1의 uv 좌표로 변환한다. 해당 좌표로 글자 판 텍스처를 샘플링하면 해당 픽셀 영역의 글자를 그려낼 수 있다. 여기까지는 단 하나의 글자를 그려낼 때 유효한 방법이다.

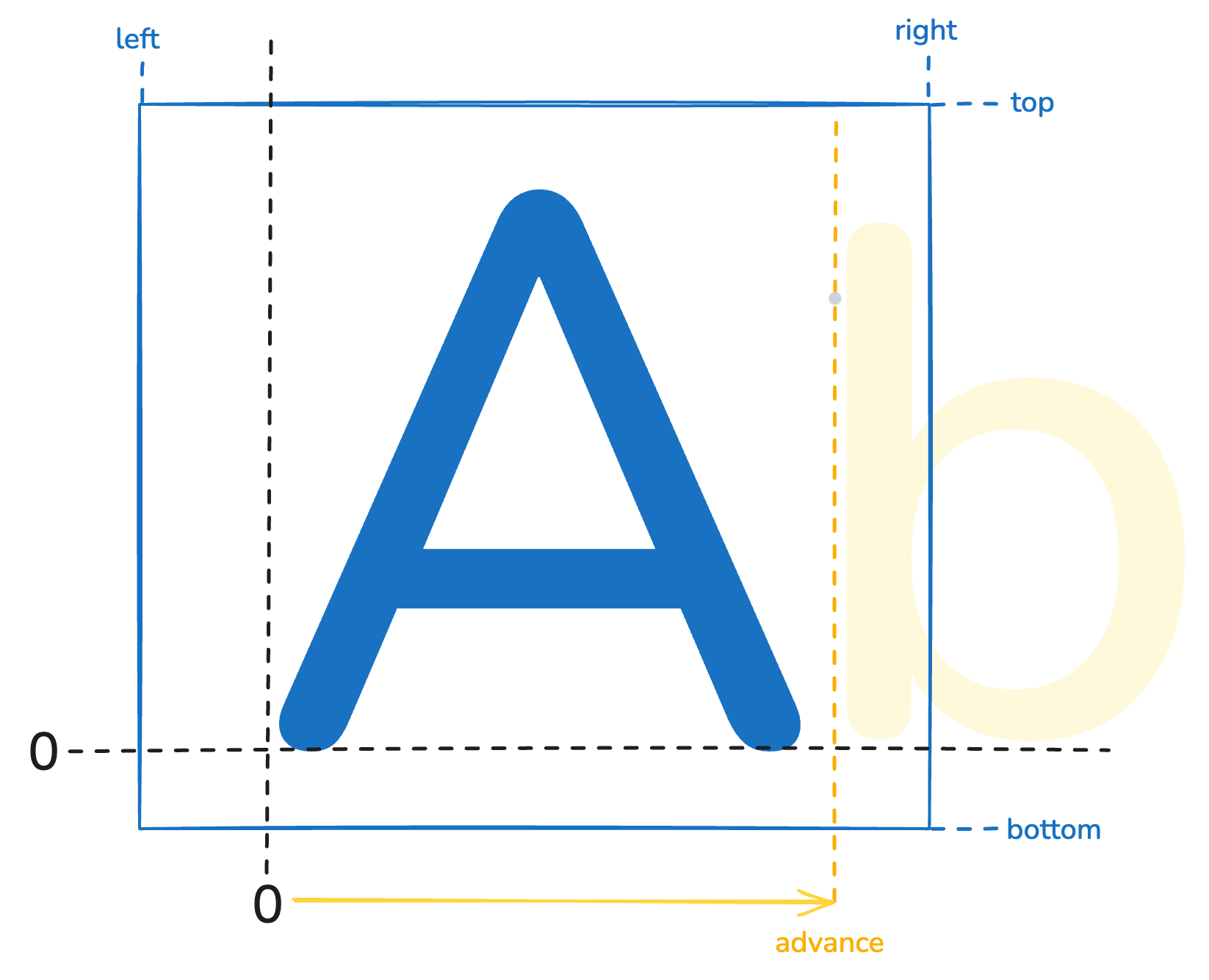
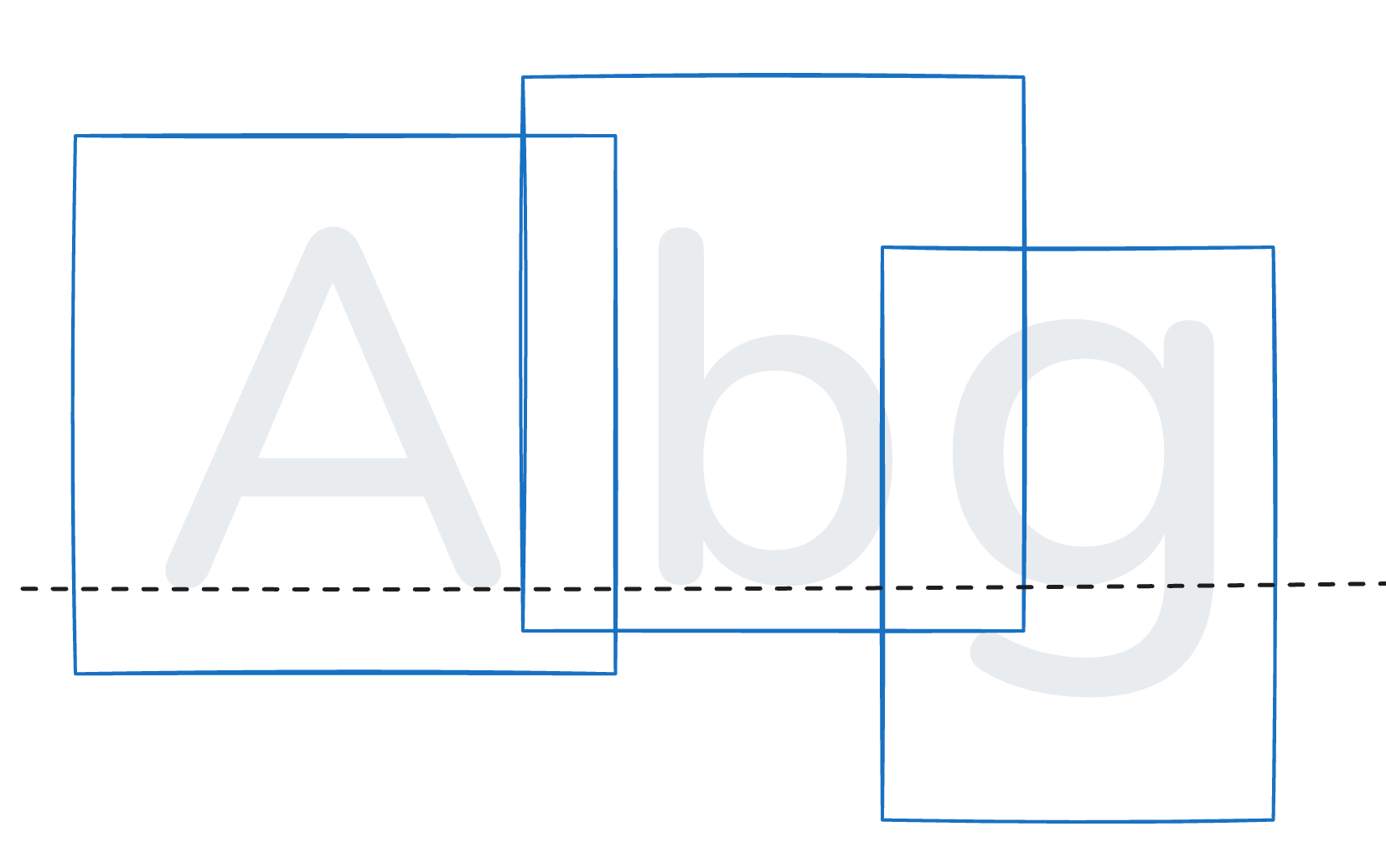

planeBounds는 글자가 배치될 때 이 글자가 차지하는 영역이다. 정확히는 베이스라인(baseline)의 y를 0으로, 이를 기준으로 하는 글리프 배치 기준점(pen) x를 0으로 하는 영역이다. 예를 들어 글자 g와 b는 서로 같은 베이스라인을 공유하지만 g는 그 기준선 아래로 그려져야 자연스럽다. 하나의 글자만을 그릴 때는 이를 신경 쓸 필요가 없지만, 여러 글자를 그릴 때 planeBounds 정보를 이용해야 한다. 그리고 advance는 글자와 다음 글자 사이의 간격이다. 이 또한 여러 글자(단어 단위)를 그릴 때 필요할 것이다.

우선 화면 좌표를 planeBounds의 영역의 로컬 좌표로 정규화시킨 뒤, 해당 글자 영역 밖의 글자들까지 그려지지 않도록 처리해주고, 이를 atlasBounds 영역에 대응시켜 베이스라인을 기준으로 하는 글자 영역을 구해, advance값을 더해주며 이 과정을 반복하여 SDF를 합치면 단어 단위의 글자를 그릴 수 있게 된다.
SDF 텍스처 값은 보통 0.5를 글자 경계의 기준으로 사용한다. 따라서 0.5보다 작다면 글자 내부, 0.5보다 크다면 글자 외부인 것이다. msdf-atlas-gen을 이용해 서체 판을 만들 때 distanceRange를 입력할 수 있었다. 이는 서체 판 텍스처가 글자 경계로부터 표현하는 픽셀 범위, 즉 글자 경계로부터 얼마만큼의 거리까지를 SDF 텍스처 값에 담을 것인지 정하는 값이다.

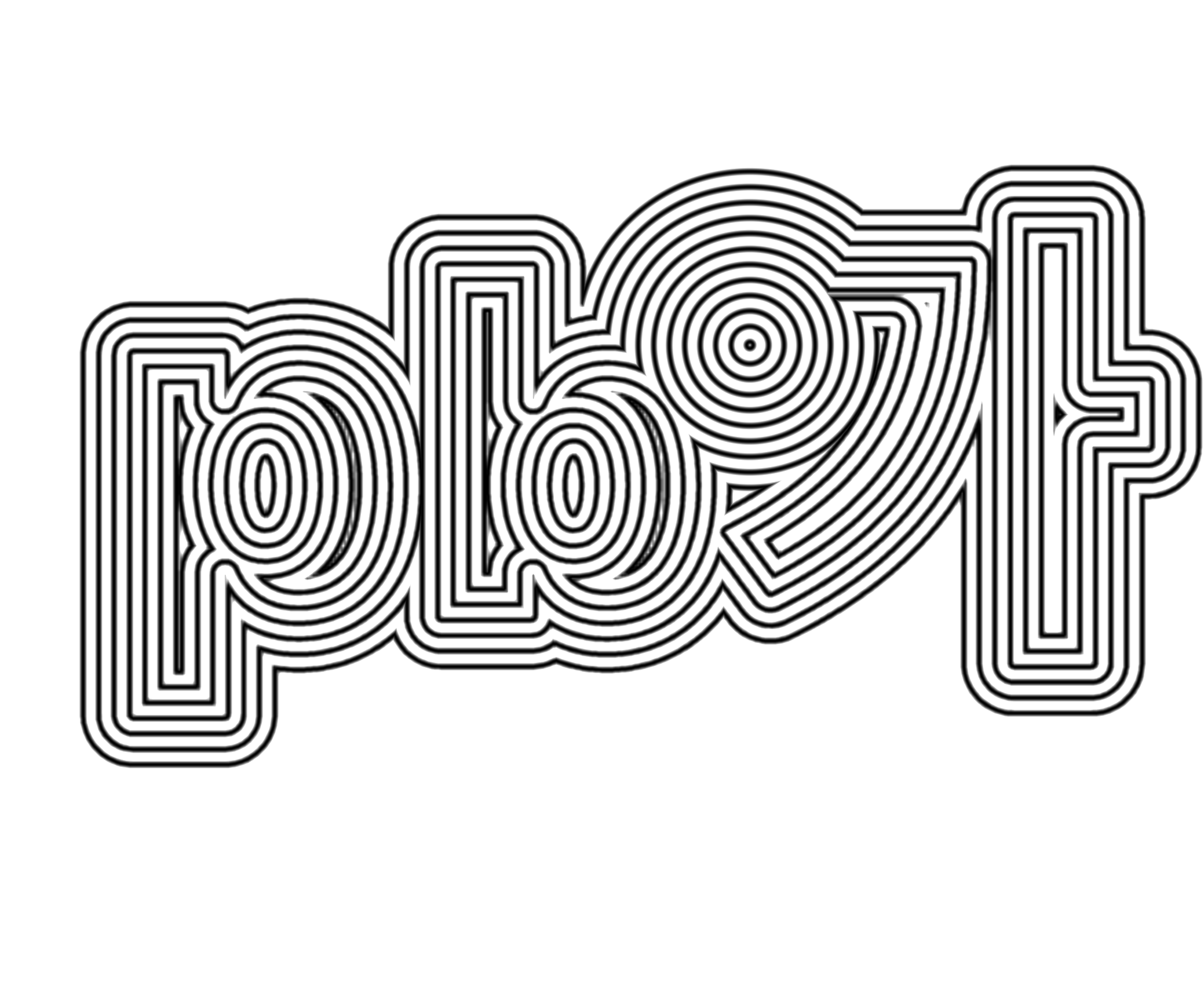
distanceRange가 36인 경우, 글자 경계 기준 안팎으로 18px의 거리 장이 0부터 1사이로 저장된다는 것이다. 바깥쪽 18px 지점이 0, 안쪽 18px 지점이 1, 글자 경계는 0.5인 셈인데, 이는 글자 영역 기준이 아니라 서체 판 텍스처 기준이다. 그저 글자 안쪽과 바깥쪽을 구분하는 데 문제는 없지만, 글자를 진짜 SDF 함수처럼 다루기 위해서는 이를 글자 영역 기준 값으로 변경할 필요가 있다. 이를 위해 픽셀 단위의 글자 판 영역 대비 글리프 레이아웃이 차지하는 영역(planeBounds)에 대한 비율을 distanceRange에 곱해 픽셀 단위의 텍스처 기준 distanceRange를 글리프 레이아웃 영역 기준 값으로 변환시켜준다. 다른 SDF 형태와 함께 사용할 때 거리 단위가 달라 문제가 될 수 있기에 조정하는 것이다. 이 부분은 GPT의 도움을 적극적으로 받았는데, 아직 이해가 잘 되지 않는다.
여기까지 글자를 그리는 WGSL 함수를 정리하면 아래와 같다. 현재는 json 파일의 정보를 손수 입력하여 글자를 그려내는 상태이다.
struct Glyph {
planeMin: vec2f,
planeMax: vec2f,
atlasMin: vec2f,
atlasMax: vec2f,
advance: f32
}
fn glyphMaxDistance(glyph: Glyph) -> f32 {
let atlasSize = vec2f(8192.0);
let distanceRange = 36.0;
let planeSpan = glyph.planeMax - glyph.planeMin;
let atlasSpanPx = abs(glyph.atlasMax - glyph.atlasMin) * atlasSize;
let planePerPx = 0.5 * (
planeSpan.x / atlasSpanPx.x +
planeSpan.y / atlasSpanPx.y
);
return 0.5 * distanceRange * planePerPx;
}
fn sdGlyph(p: vec2f, glyph: Glyph) -> f32 {
let planeSpan = glyph.planeMax - glyph.planeMin;
let t = (p - glyph.planeMin) / planeSpan;
let atlasSize = vec2f(8192.0);
let distanceRange = 36.0;
let maxD = glyphMaxDistance(glyph);
let inside =
step(0.0, t.x) *
step(t.x, 1.0) *
step(0.0, t.y) *
step(t.y, 1.0);
if (inside < 0.5) {
return maxD;
}
let atlasUv = mix(glyph.atlasMin, glyph.atlasMax, t);
let sample = textureSampleLevel(test_tex, test_texSampler, atlasUv, 0.0).r;
return (0.5 - sample) * 2.0 * maxD;
}
fn sdText(p: vec2f)->f32{
var d = 1.0;
var pen = vec2f(0.0);
let glyphP = Glyph(
vec2f(-0.07008682720282626, -0.32252701579384874),
vec2f( 0.71461807720282633, 0.66167913549459689),
vec2f(3964.5 / 8192.0, 1.0 - 155.5 / 8192.0),
vec2f(4082.5 / 8192.0, 1.0 - 303.5 / 8192.0),
0.626953125
);
d = min(d, sdGlyph(p - pen, glyphP));
pen.x += glyphP.advance;
let glyphB = Glyph(
vec2f(-0.07203995220282626, -0.12967581047381546),
vec2f( 0.71266495220282633, 0.82793017456359108),
vec2f(8073.5 / 8192.0, 1.0 - 659.5 / 8192.0),
vec2f(8191.5 / 8192.0, 1.0 - 803.5 / 8192.0),
0.625
);
d = min(d, sdGlyph(p - pen, glyphB));
pen.x += glyphB.advance;
let glyphGa = Glyph(
vec2f(-0.11991749, -0.21612635),
vec2f( 0.97733937, 0.92768080),
vec2f(2248.5 / 8192.0, 1.0 - 7846.5 / 8192.0),
vec2f(2413.5 / 8192.0, 1.0 - 8018.5 / 8192.0),
0.8642578125
);
d = min(d, sdGlyph(p - pen, glyphGa));
return d;
}이를 더 손쉽게 사용할 수 있도록 만들려면 현재 WebGPU API 사용 환경 기준 글자 정보, 즉 위 코드의 Glyph 구조체 부분을 JS에서 GPU로 전달할 필요가 있다. WebGL 환경에서 작업할 때는 글자 정보를 텍스처로 셰이더 프로그램에 전달하는 신기한 경험을 했었는데, WebGPU 환경에선 스토리지 버퍼(storage buffer)를 이용하면 되기에 훨씬 직관적이고 안정적이다.
지금까지의 결과물로 글자를 그려내는 것 자체는 문제가 없지만, 유니코드 정수를 이용해야 되기에 원하는 글자를 직관적으로 그릴 수 없다는 불편함이 있다. 이를 해결하기 위해 JS에서 문자열을 다루고 이에 해당하는 글자 정보를 직접 셰이더에 전달해 사용하는 방법 등 여러 고민을 해 보았으나, 결국 셰이더 코드 내에서 직접 문자열을 사용할 수 없다면 그 어떤 방법도 차선책에 불과함을 인지하게 될 뿐이었다. 그러나 다행히도 WebGPU를 다루기 위해 Codex와 함께 제작한 셰이더 코드 빌더를 이용하고 있었기에 직접 셰이더 코드 내의 문자열을 32비트 유니코드 양의 정수로 변환하여 파이프라인에 끼워 넣는 작은 전처리기를 만들기로 한다.
우선 서체의 유니코드와 입력한 글자의 유니코드를 비교하여 서체 데이터 내에서의 글자 인덱스를 반환하는 함수를 만든다. 해당 함수를 이용해 셰이더 소스코드 내의 sdGlyph 함수를 JS 문자열 정규식과 replace 메서드로 두 번째 인자 부분을 문자열에서 32비트 양의 정수 글자 인덱스로 변경하여 반환한다. 단어 단위 글자의 경우, JS에서 두 형태를 합치고 advance를 더하는 동작을 글자 수 만큼(글자 인덱스 길이 만큼) 반복하는 셰이더 코드를 반환하는 함수를 만들고, 마찬가지로 sdText 함수를 replace 메서드로 반환하게 하였다. JS 문자열 정규식은 쳐다보기만 해도 속이 안 좋아져서 GPT에게 작성을 부탁했다. 여기까지 한 이후 Codex에게 기존 셰이더 빌드 과정에 병합을 부탁하여 완성했다.
export function textToIndices(text, fontData) {
//폰트 유니코드 정보
let glyphUni = fontData.glyphs.map((glyph) => {
return glyph.unicode;
});
let indices = [];
//모든 문자를 조합된 유니코드로 보기 위해 NFC 규칙으로 정규화
for (const char of text.normalize("NFC")) {
const unicode = char.codePointAt(0);
let idx = glyphUni.findIndex((code) => {
return code === unicode;
});
if (idx < 0) {
throw new Error("textToIndices: 무언가 좋지 않은 일이 일어났습니다.");
}
indices.push(idx);
}
return indices;
}
function compileText(source, fontData) {
const sdTextPattern =
/sdText\s*\(\s*((?:[^(),"']|\((?:[^()"']|\([^()]*\))*\))+?)\s*,\s*"([^"]*)"\s*\)/g;
let sdTextFunc = "";
let funcIndex = 0;
let res = source.replace(sdTextPattern, (match, pos, text) => {
const funcName = `__sdText_${funcIndex}`;
funcIndex += 1;
const indices = textToIndices(text, fontData);
sdTextFunc += createTextFunc(funcName, indices);
return `${funcName}(${pos.trim()})`;
});
return `${sdTextFunc}\n${res}`;
}
function createTextFunc(name, indices) {
//r은 indices를 반복하는 코드 뭉치
let r = "";
for (let i = 0; i < indices.length; i++) {
r += `\nd = min(d, sdGlyph(p - pen, ${indices[i]}u));
pen.x += glyphTable[${indices[i]}u].advance;`;
}
return `fn ${name}(p: vec2f)->f32{
var d = 0.5 * fontInfo.distanceRange / fontInfo.atlasScale;
var pen = vec2f(0.0);
${r}
return d;
}\n`;
}
function compileGlyph(source, fontData) {
const sdGlyphPattern =
/sdGlyph\s*\(\s*((?:[^(),"']|\((?:[^()"']|\([^()]*\))*\))+?)\s*,\s*"([^"]*)"\s*\)/g;
return source.replace(sdGlyphPattern, (match, pos, text) => {
const indices = textToIndices(text, fontData);
if (indices.length !== 1) {
throw new Error(`sdGlyph에는 한 글자만 사용할 수 있습니다: "${text}"`);
}
return `sdGlyph(${pos.trim()}, ${indices[0]}u)`;
});
}
export function compileTextLiterals(source, fontData) {
let code = source;
code = compileGlyph(code, fontData);
code = compileText(code, fontData);
return code;
}마무리
내 목표는 WebGPU 환경, 특히 프라그먼트 셰이더 만을 활용하는 환경에서 화면에 글자를 그리는 것이었다. 이를 위해 SDF 서체 판을 제작하였다. SDF 서체 판은 서체 파일의 모든 글리프를 SDF화 하여 묶어 놓은 하나의 큰 이미지 파일이며, 해당 이미지 파일의 어느 위치에 어떤 글자가 있는지 등의 서체 정보를 담고 있는 json 파일과 함께 사용된다.
이에 셰이더 프로그램에 해당 이미지를 텍스처로, 서체 정보를 스토리지 버퍼로 전달하였다. 셰이더 프로그램 내에서 글자 판 어느 위치에 어떤 글자가 존재하는지, 그 글자가 그려질 때 베이스라인을 기준으로 어느 정도의 글자 영역을 가지고 있는지, 그리고 한 글자가 그려진 뒤 다음 글자가 그려질 때 어느 정도의 간격이 필요한지 등의 정보를 이용해 원하는 글자를 그려낼 수 있었다.
하지만 셰이더 코드가 문자열 자료형을 지원하지 않기에, 오직 셰이더 코드 내에서 글자를 그려내기 위해 해당 글자의 순번(2350자의 서체 판이라면 몇 번째인지)을 이용해야 했다. 이는 단일 글리프를 그려내는 데엔 큰 문제가 없을 수 있지만, 단어 단위의 글자 묶음을 그려내는 데엔 상당한 피로감을 유발한다. 예를 들어 “가나다” 세 글자를 그리려면 172u, 194u, 220u의 요소를 가진 배열을 만들어야 하고, 그 길이 또한 직접 선언해야 하는 식이다. 더욱 끔찍한 점은 서체 판을 교체하면 순번 자체가 전부 달라진다는 것이다. 다른 방법을 모색할 필요가 있었다.
여러 방법을 검토하던 중, 마침 자체 제작 셰이더 빌더를 사용 중이니 셰이더 코드 내의 문자열을 글자의 순번으로 파싱하는 방식이 으뜸이라 판단하였다. JS에서 문자열 배열을 유니폼이나 스토리지 버퍼로 넘기는 방식도 가능했지만, 내가 원한 것은 셰이더 코드 안에서 sdText(p, “가나")처럼 자연스럽게 작성하는 경험이었다. 즉, 런타임 데이터 전달보다는 “셰이더 작성 방식 자체를 확장하는 일”에 가까운 문제였다.
그래서 셰이더 코드가 실제 WebGPU 파이프라인에 전달되기 전 JS 단계에서 한 번 전처리하도록 만들었다. 빌더가 셰이더 문자열을 훑어 sdGlyph(p, “가")나 sdText(p, “가나") 같은 호출을 찾아내고, 이를 폰트 데이터의 글리프 인덱스로 치환한다. 예컨대 “가” 폰트 테이블에서 해당 유니코드와 일치하는 글리프를 찾아 172u 같은 숫자 인덱스로 바뀌고, sdText는 여러 글리프 인덱스를 순서대로 그려 내는 WGSL 헬퍼 함수로 변환된다.
이 방식의 장점은 셰이더 내부에서는 여전히 사람이 읽기 쉬운 형태로 코드를 작성하면서도 GPU에 전달되는 최종 코드는 정적인 숫자 인덱스와 명시적인 WGSL 함수로 구성된다는 점이다. 덕분에 WebGPU 셰이더 자체는 문자열을 직접 다룰 필요가 없고, 복잡한 문자열 처리 문제는 JS 빌드 단계에서 깔끔하게 해결된다.
이번 경험을 통해 프레임워크(와 비스무리한 무언가)를 직접 만들 때 얻을 수 있는 강력한 이점을 체감했다. 단순히 편의 함수를 몇 개 추가하는 수준이 아니라 내가 원하는 사고방식에 맞추어 코드 작성 문법과 제작 흐름 자체를 설계할 수 있다는 것이다. 기존 도구를 쓰는 입장에서라면 그저 받아들여야 했을 제약을 직접 만든 빌더 안에서는 내 목적에 맞게 재구성할 수 있었다.